TA的每日心情 | 怒
2023-3-8 00:39 |
|---|
签到天数: 4 天 [LV.2]偶尔看看I
|
本帖最后由 instrumental 于 2021-3-18 04:18 编辑 % B4 G; _5 [3 r% v9 x& B
8 [* z& h- T% g# X1 D/ R8 R8 DFastWordQuery
. c8 a& E- Z( D6 O% z6 [+ A. `6 F6 s% n% G3 w
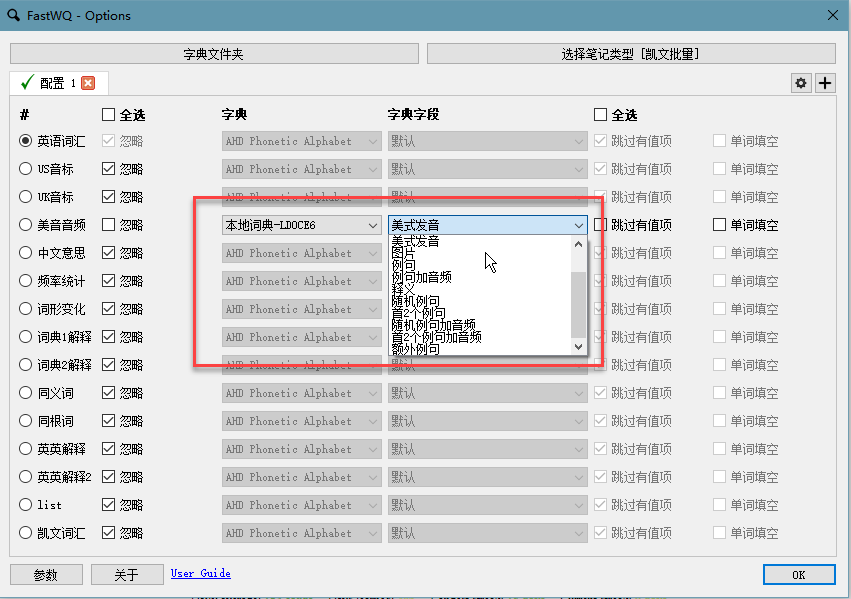
在为[[Anki]]制作单词卡片的时候,发音一直是一个比较头痛的问题。
4 S5 j7 d2 H. ]! j有道的发音是比较容易获取的,但是有道的发音不纯正,很多音读得不是非常正确。2 i; O$ \# F1 ]! c
TTS也不能与真人发音相比,而且机器合成音在背单词的时候会有不良影响。7 ^- v3 p. B9 d" n7 J$ [6 e
相对来讲朗文词典的真人发音就非常的纯正。
4 W& F' p, m+ \ L所以FastWQ特别针对朗文mdx词典制作对应的字典查询服务,以便快速的为单词添加读音并下载音频到本地。
* c2 ?/ {# b( s+ x- r) x) S# q- {按照以下步骤,可以很方便的为整个单词本快速的添加音频。: G4 y8 I% ]/ x1 g5 e
! N5 w( n: ^" D2 F' `! t使用的时候切记不要导入词典而是直接去设置py, E0 x/ U8 |% }; N& [" j& R
+ P- J+ f; u5 q: [1 H; d! c特制的朗文 6 本地词典
* k+ k5 Q9 B0 `7 S+ W+ S! {5 Z6 i ~5 k( @: P
- 1b5de81464fb46ca892eab4a698a207e#1b5de81464fb46ca892eab4a698a207e#1206#/LDOCE6双解 修改 可提取音频/entry.js, d1 `% Z6 a9 u3 t9 h
- f24817ae7bc736d4365908da3f87f77f#efd11ff3580a0f7dc0735119d296cf98#1297932816#/LDOCE6双解 修改 可提取音频/L6mp3.mdd
$ p% h% K; q' A* S# n, u5 b# t - ee13707d1b966a49bc3149b111cd6b4d#60a7f4d9a40eb2359b4ece19876f584d#26550272#/LDOCE6双解 修改 可提取音频/L6mp3.mdd.db
3 r) X( t& s5 f - 7f301751b90d10f33412de45a599f2da#60a24ed264dc49dd7a8b05a1ace848cf#124057083#/LDOCE6双解 修改 可提取音频/L6mp3.mdx
+ X' f: S6 s$ q: H3 h, @/ c - aefbf1c0cae35980122ace73f533409e#df04641926e6d88694ecee7dcada3d19#11501568#/LDOCE6双解 修改 可提取音频/L6mp3.mdx.db
# F' m8 @& P' N) h - e79f484789815550da723c944b8f27d8#e79f484789815550da723c944b8f27d8#12642#/LDOCE6双解 修改 可提取音频/LDOCE6.css
; y4 Z- ]) R, r! B' U; X& q修改程序的YHCD,然后用正则表达式制卡就好了; F4 v3 N$ J& s% V+ h
# Q' M) { [, L4 _ Q
* q. U+ W# F, T# M
1 ~. x7 M7 y$ @- - [FastWordQuery - GitHub](https://github.com/sth2018/FastWordQuery)
2 C0 G* `% n) P6 T" M0 q - - [为单词添加真人发音(朗文 mdx 词典)](https://sth2018.github.io/FastWordQuery/docs/get_mdx_ldoce6_sounds.html)- Q) K9 t: h, j! n& y; Q: ?
- - [anki 神级插件 fastWQ 提取本地朗文音频・语雀](https://www.yuque.com/purequant/anki/sudl9z)
0 s! P3 M7 K& S0 O$ l* P. Z5 b0 D$ f% S0 H& L
) n' I; b/ G3 R1 T1 J, S( z' K( r
, |2 ^7 v' p+ `/ E" X% O( q# Y5 O% T4 u F- L# a6 P1 S% K
4 u u4 H8 I3 p) ~5 a7 Y/ c8 R: m8 P: Y0 Q2 F3 ^0 E
5 @$ @6 P' O% L( ? C' P8 M1 `' C% c6 V% H! f) n
7 r! ?! l r- k( Z/ B, K
* p. `5 N$ @% h% V# m7 `9 p% Y( j2 Y% X# C
/ O. d: R I& R* `, M" _" j
4 a7 N% z1 P7 j+ H1 c
1 ?- ~6 Y. [$ b- O
1 d4 P' S7 b) B7 j8 v; S# R7 g( Z. ~; G4 r& y# k, j& U
7 c, S2 i: q/ u+ m }( m' B$ |$ Y6 O2 E6 o
- #-*- coding:utf-8 -*-
' W& h# a5 D0 X- j# m - import os
2 W v5 U6 b. K1 ?& D - import re
7 K- O7 N5 {3 O, S8 y0 n9 F - import random
e3 T$ M* s6 r/ P- {! z: z - from ..base import *
# K( h: Z% |" M' A9 I# g - ! p1 Q) o' e$ p; ]' z3 R
- VOICE_PATTERN = r'<a href="sound://([\w/]+\w*\.mp3)"><img src="img/spkr_%s.png"></a>'- V. N+ D, `( H' n- u8 Q2 }- Q
- VOICE_PATTERN_WQ = r'<span class="%s"><a href="sound://([\w/]+\w*\.mp3)">(.*?)</span %s>'! }: [6 U" q4 j$ n0 o
- MAPPINGS = [
* L8 o0 `% A+ f - ['br', [re.compile(VOICE_PATTERN % r'r'), re.compile(VOICE_PATTERN_WQ % (r'brevoice', r'brevoice'))]],, A8 {4 n0 C1 @$ g- A
- ['us', [re.compile(VOICE_PATTERN % r'b'), re.compile(VOICE_PATTERN_WQ % (r'amevoice', r'amevoice'))]]; k5 U0 M! @6 _& Y8 C
- ]
; z& k2 i$ O: p6 x: Z9 [) F1 f+ t - LANG_TO_REGEXPS = {lang: regexps for lang, regexps in MAPPINGS}
) F8 V b4 B) i) \ - DICT_PATH ='D:\\111111111111111111111111111111.mdx.mdx', d* K& l0 z7 {5 S1 _0 E" i& W h
6 o) M6 H' j) T" `4 g- m- : s- w+ W" U9 e
- @register([u'xxxxx', u'xxxxx'])# v% R }4 r3 |/ B/ }% q* @2 t
- class xxxxx(MdxService): O7 J& Z7 L+ s ~! Q; Z
0 I9 R: n# A4 _, v {- _1 u& m- def __init__(self):
0 i3 B+ ~& O. K2 P* B+ ] - dict_path = DICT_PATH
/ N+ v5 k1 ]2 z% P - # if DICT_PATH is a path, stop auto detect
; ?) x( M" x6 v- y- p# M - if not dict_path:; ?; ~- q7 c+ u% j1 M8 M* Y9 D/ Q
- from ...service import service_manager, service_pool
" p. f! ?, F I6 |3 }6 l - for clazz in service_manager.mdx_services:! f7 Y3 _- [" |
- service = service_pool.get(clazz.__unique__)
/ E) J7 {: F e+ j) p3 l - title = service.builder._title if service and service.support else u''
+ T% `7 j& C7 A8 x3 X* C - service_pool.put(service)
/ K7 |* T' t$ z - if title.startswith(u'LDOCE6'):
9 G) r1 p( ] c- A7 b8 } - dict_path = service.dict_path) Q0 j9 n) [# S2 @5 H
- break
7 ?2 K5 G, ~4 |% F - super(xxxxx, self).__init__(dict_path)/ p& L% P7 e! r
: o9 t4 G8 c4 w$ Y5 }* v! p% |- @property
# l5 ^/ s6 n9 W J- f - def title(self):
) R! \+ E+ f5 ~! t - return getattr(self, '__register_label__', self.unique). s- p6 s6 z1 S( V# o
- ' C {7 ~" Z7 \( G# D# c
- @export('PHON')
; C; m& p& |0 s% u - def fld_phonetic(self):
; }* G+ c2 _8 x" ?8 f4 n - html = self.get_html()) @8 r! l* F, C9 G
- m = re.search(r'<span class="pron">(.*?)</span>', html); Q: ]: d$ g' H, Z Z
- if m:, X, O! j9 r) B( M" f
- return m.groups()[0]
0 Z* _8 ^- e3 P+ ?5 c6 ~1 j - return ''
& [& `$ {2 \2 u% \# p8 r
3 A# s/ z- z$ a) Q3 N* _- def _fld_voice(self, html, voice):4 N0 t+ _& e, T! I% d
- """获取发音字段"""* K8 p$ h- O3 X/ C3 A
- for regexp in LANG_TO_REGEXPS[voice]:) a3 C0 Q3 A: B, S
- match = regexp.search(html)5 ]9 D% M- ~: f( d! t; N. F
- if match:' Z% R% d& q" c3 k" ^( f1 L
- val = '/' + match.group(1)
0 X6 Y8 ^) A3 D- _; p l2 } - name = get_hex_name('mdx-'+self.unique.lower(), val, 'mp3')% j3 O3 B, S' `
- name = self.save_file(val, name)
' g( v2 Z. M) f! v - if name:
8 Y E$ |( r* a - return self.get_anki_label(name, 'audio') X! [! A# \" |: {4 r1 E% N+ I
- return ''
. u! l! P! D4 u8 b* N$ e - # Y2 N+ V; c2 e3 p5 w& b' z
- @export('BRE_PRON')
/ H% |# x; R5 E; c5 A& z/ g; k E - def fld_voicebre(self):
7 O+ ~& v% ?$ I8 f( Z - return self._fld_voice(self.get_html(), 'br')
; C( P; s7 A' P6 }- S5 s - ! D X% Z- a+ a& S8 P7 f
- @export('AME_PRON')) F' s# P t; E3 C
- def fld_voiceame(self):
4 _2 B4 x& M3 h# n: \ - return self._fld_voice(self.get_html(), 'us'). s* l# s! L" T2 x" Y. P
- 0 c k6 ~6 o, y8 \* I
- def _fld_image(self, img):
$ t' w: F) L) g+ Y - val = '/' + img
C/ S1 O: `+ K( z% i1 l- p/ C1 Y - # file extension isn't always jpg
3 f" p9 j3 G$ t - file_extension = os.path.splitext(img)[1][1:].strip().lower()
% \: I. Y' a0 I: h) D. W/ v - name = get_hex_name('mdx-'+self.unique.lower(), val, file_extension)- V& I( p5 z5 |2 f- e
- name = self.save_file(val, name)' k# u- {& |9 @
- if name:
, z- z/ Z4 R/ \2 Y - return self.get_anki_label(name, 'img')
7 M j$ z2 c# \7 v9 \) r - return ''
, O5 g$ I6 I- L7 X5 W - 6 A! B `% j4 A8 E I
- @export('IMAGE')! N# f- r9 Y6 l8 @* k; c
- def fld_image(self):: X3 r0 R" [1 v. z3 v4 V0 o
- html = self.get_html()
! Q5 F: o2 S, t, r% L8 Y4 b+ D - m = re.search(r'<span class="imgholder"><img src="(.*?)".*?></span>', html)4 O/ [: v3 D1 @
- if m:" O, E' [* K, t, J
- return self._fld_image(m.groups()[0])
x: Y+ U% O7 K% ~) F6 M8 Y - return ''
( a- p6 X3 Q" [ - ; M# e' e' E$ t; v5 H$ ]+ ?- j
- @export('EXAMPLE')
, r3 V5 s7 o9 Z! s - def fld_sentence(self):7 P; |8 ?. w+ H; D
- return self._range_sentence([i for i in range(0, 100)])0 j4 G4 P# `2 L& D
- ( @: G, R. ~ z2 }7 L7 R: k
- def _fld_audio(self, audio):' J1 G5 u2 a1 A- b
- name = get_hex_name('mdx-'+self.unique.lower(), audio, 'mp3')( s; O( Y. t- j% Z0 T. c; r
- name = self.save_file(audio, name)5 n. O4 ?9 o( y; i3 Z5 V2 X
- if name:4 l2 N& q2 Z D/ U5 u
- return self.get_anki_label(name, 'audio')
+ y% Z7 } P3 S! I; }: S9 ^" P( T7 A! D - return ''
4 t* c$ {9 V/ r
1 O' d" V; b2 j# s3 H3 @! Q, e- @export([u'例句加音频', u'Examples with audios'])7 y% ^! c8 v8 ~
- def fld_sentence_audio(self):4 a) \) ]: N/ A! L& U7 l$ W- [ f& \
- return self._range_sentence_audio([i for i in range(0, 100)])6 `( y6 E$ m- ?; S9 ? i
; B, L3 b& @2 b7 W- @export('DEF')
U3 R( Q( X4 j" d# K) G" W9 j$ b - def fld_definate(self):$ U* X. Z! q* \5 f: F5 Y
- m = m = re.findall(r'<span class="def"\s*.*>\s*.*<\/span>', self.get_html())6 G9 j# w7 Z! k# ^2 b
- if m:
: ^( z% E5 q @6 A& q$ a3 G( B - soup = parse_html(m[0])
; Z/ E d' E* D: ]4 Y) Q - el_list = soup.findAll('span', {'class':'def'})
' s& B# g' ]9 @9 a- Q! V - if el_list:
( o @9 ~0 G3 Z& y% \ - maps = [u''.join(str(content) for content in element.contents)
7 Y2 V! R: |( x# A7 M1 Q1 L& w/ x: p - for element in el_list]3 R8 Q& B+ {, L/ ?/ w
- my_str = '') p$ C, l1 \! ?3 w/ v2 [3 \ h
- for i_str in maps:5 N: G5 Q/ q) Q+ e) h* z' S8 e
- my_str = my_str + '<li>' + i_str + '</li>', x b6 i: j8 ]! k: w
- return self._css(my_str)
Q+ m% G$ F: R3 M2 }# c7 T- E- V - return ''
& x8 D. P! u) f- l; _6 L: e - 9 j2 ~8 Q0 n4 G4 Y* m) ~ S
- @export([u'随机例句', u'Random example'])" E7 x3 b) J% |! [ D
- def fld_random_sentence(self):6 S9 P- r: f9 w$ a+ h3 O, r
- return self._range_sentence()
& q" j: \; R# ~ - 4 E" w3 p1 P3 S6 b' o; I3 B( G. G+ Z
- @export([u'首2个例句', u'First 2 examples'])% n8 l* N* ]0 H% u* ^" q2 f
- def fld_first2_sentence(self):: k- }+ E7 Y4 v$ ?4 L0 b
- return self._range_sentence([0, 1])- P6 ~% I: c; A& T5 h! K a$ ]. d
-
- z/ W6 q" v! j; W6 }: Q - @export([u'随机例句加音频', u'Random example with audio'])$ b9 K5 |2 h D
- def fld_random_sentence_audio(self):( @* R$ _. J1 [8 u* U
- return self._range_sentence_audio()8 J" N! }1 M7 a" c, f+ C. ~4 q; l
0 h( Y4 @" L9 e- @export([u'首2个例句加音频', u'First 2 examples with audios'])
* R: k( q7 N# T1 ~3 X7 o" e0 z; @ - def fld_first2_sentence_audio(self):# Y1 ?3 \& T' F
- return self._range_sentence_audio([0, 1])! l3 Y. t9 a, A* H
/ e- s/ X- E9 i: W s ?- def _range_sentence(self, range_arr=None):4 P9 S# u% u( ~( X5 Y- i
- m = re.findall(r'<span class="example"\s*.*>\s*.*<\/span>', self.get_html())2 @0 v/ V$ d2 d5 {7 q
- if m:
: l _, E- ?) _2 Y& P4 I - soup = parse_html(m[0])
2 k+ b5 F* B# `, V0 p& r' ` - el_list = soup.findAll('span', {'class':'example'})
4 g j- C: q! x& O& u9 Z - if el_list:1 q. _' Z( ~7 ?" T- Q
- maps = [u''.join(str(content) for content in element.contents)
; w8 T/ f- K) P3 P: O - for element in el_list]0 x) `" Q% X7 s8 i, m' Z: l8 W
- my_str = '', C8 p K8 V4 v. H
- range_arr = range_arr if range_arr else [random.randrange(0, len(maps) - 1, 1)]
+ [0 U$ g& b5 _ - for i, i_str in enumerate(maps):# i8 E( {" ]* {7 f
- if i in range_arr:
# G* ~/ F7 O& ]$ v L$ r - i_str = re.sub(r'<a[^>]+?href="sound\:.*\.mp3".*</a>', '', i_str).strip()
4 H2 |- Q: G* g6 r- w - my_str = my_str + '<li>' + i_str + '</li>'
) n2 C0 K% d- c6 h. \( t& B3 F - return self._css(my_str) S, T! T" ^1 Z! X* T3 N6 S- A
- return ''
H6 p' ?6 j8 L; Q6 W
$ B6 W( x" N) W- def _range_sentence_audio(self, range_arr=None):
# y7 [2 l. R+ V8 m# `+ N - m = re.findall(r'<span class="example"\s*.*>\s*.*<\/span>', self.get_html())% p# T0 Y. C2 l- X( I
- if m:
; {: P$ {& |3 W" E. p - soup = parse_html(m[0])/ t& Q+ R3 w/ x
- el_list = soup.findAll('span', {'class':'example'})
6 F R7 ^, [$ \# ]! Q4 Y) q. W - if el_list:
" p1 _) Z( R1 Y& q0 S$ X - maps = []' a1 M6 P. e' g" ~
- for element in el_list:
: u7 @1 p& f) i2 C - i_str = ''
$ f9 {7 Q9 j4 Z# b+ J - for content in element.contents:/ T6 B3 ]2 ?! \7 M( M4 u# b
- i_str = i_str + str(content)
& a- I6 X7 d% {4 E - sound = re.search(r'<a[^>]+?href="sound\:\/(.*?\.mp3)".*</a>', i_str): ]/ K* Y( B2 c: b3 u* v. l
- if sound:) P2 I+ A4 e N. @' x8 T
- maps.append([sound, i_str]), y5 h& K& k- Q& v
- my_str = ''% L- U' f6 R3 P& \9 ?
- range_arr = range_arr if range_arr else [random.randrange(0, len(maps) - 1, 1)]( @8 Q0 T$ |. f! J/ O, [- G
- for i, e in enumerate(maps):/ c4 t$ p# k; e3 P
- if i in range_arr:9 x' h5 } d% P8 f3 j1 X5 B
- i_str = e[1]7 v; [+ A9 M& G0 [% G5 o
- sound = e[0]4 S2 l5 H! L4 u: }
- mp3 = self._fld_audio(sound.groups()[0])+ O6 _6 H! N, f, y
- i_str = re.sub(r'<a[^>]+?href="sound\:.*\.mp3".*</a>', '', i_str).strip()0 ]. T* J6 a; G) {
- my_str = my_str + '<li>' + i_str + ' ' + mp3 + '</li>'1 R- x7 e1 E% g# M' _. |6 N" x2 ^
- return self._css(my_str)) P* n Y. `% |2 q/ `
- return ''! a$ x! L/ n' {% u2 @. K9 `" Z
4 W5 B5 M$ _* ^5 Z* s- @export([u'额外例句', u'Extra Examples'])
e6 S% J7 i& i8 F9 R3 o - def fld_extra_examples(self):0 z6 v) u7 Y5 {0 B
- lst = re.findall(r'href="/(@examples_.*?)">.*?<', self.get_html())
6 `1 I* C) u: f$ {; B% T - if lst:2 d9 }" u' s, @/ J
- str_content = u''5 f) y7 D4 {$ Q
- for m in lst:
, g* L& C: f( i7 q. o! C" [1 g" K - content = self.builder.mdx_lookup(m), l% _. }' P& q8 y9 T+ H) c
- if len(content) > 0:
3 e5 o% v$ a" E. Z - for c in content:
1 J1 j7 ]- R7 L4 q - str_content += c.replace("\r\n","").replace("entry:/","")9 m: A% f; L! y: |
- return self._css(str_content)+ C4 r( { O* n
- return ''
* A' y9 U* ?4 h# V& D$ b - * U* x- {* I) B
- @with_styles(cssfile='_ldoce6.css')0 X) C' m" X2 L \4 s* C
- def _css(self, val):
( y% e) B7 u( z, i/ ], S5 _ - return val
7 v+ R4 n: R# c4 p; [2 I9 A/ j( m4 {. i -
* E# _; T2 c) i5 Z" q8 J9 O* U5 n- F% u+ b3 q- l. c" M. R
- 2 K1 F$ ^4 z$ X, m3 t& v
- ^([^\t]*)\t(.*)- F. z; q+ p9 j
- \1\n<link type="text/css" rel="stylesheet" href="LDOCE6.css"/><div id="LDOCE6_Zzz_1"><span class="entry" id="zzz" new="NewInLdoce"><span class="entryhead"><span class="hwd"></span><span class="hyphenation"></span> <span class="brevoice"><a href="sound://\2"></span brevoice><img src="img/spkr_r.png"></a> <span class="amevoice"><a href="sound://\2"></span amevoice><img src="img/spkr_b.png"></a><span class="buttons"></span></span><span class="sense" id="zzz_s1"> <span class="def"></span def></span></span></div><script src="entry.js"></script>\n</>
! i0 H% \8 l$ u/ J& k) I% {" N5 d P! v, p: J$ E
有点复杂就说下原理,懂的人自然懂8 B! K8 ]4 B5 |1 K. x& \
+ t: U$ K8 U+ c: I& `5 r" z0 AFastWordQuery的作者特别做了朗文 6的支持,包含 .py 文件 特制的 mdx mdd/ _% @! n3 J7 U( `
1 P" T# Q. ~5 L4 E% t- P4 H" C我就根据那个特制的MDX直接造了新的mdx出来,然后就支持了.
/ F; T, t; e- h& s5 o3 G, [' G, \py代码比较复杂看不懂,我只是改了里面的词典名 xxxxxxx
1 G* z/ m6 f1 m$ I: _7 o
: K& u u: ]* X然后正则表达式是用来制作mdx的
- c1 U" t: @# `/ a1 o8 C4 K c2 X3 I: B' K
词头\tMP38 e3 U) B# |/ \1 ]
: Z" ]: b& U% ?
7 l4 W/ ^, A z想想应该也没几个人用得上,学英语以外的外语的人应该不多8 |5 ~+ h( q. V; H% V
4 |3 y! u# Y/ s1 g u8 g! C J( f( f3 F
$ I4 k! Y; F6 h1 I2 t8 T* l
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?免费注册

x
评分
-
1
查看全部评分
-
|


 发表于 2021-3-12 17:53:08
发表于 2021-3-12 17:53:08


