|
|
本帖最后由 eeshu 于 2020-8-3 13:01 编辑
- G. \0 b/ g3 V0 M) |/ z2 |( M- O. |# Y! D$ u) H6 L
谢谢大家。经过重新裁页和拼接再转存,已经成功提取所有文本。第一次失败估计是中间环节使用了一些打包工具造成的。: ], z2 t) @! p% R- A
第二次全程只用了acrobat,没有问题了。
9 Y' J+ w" I+ X- g9 `
4 Q7 u: T+ s) u- S; v C0 G' p- t- ?7 r# S! |
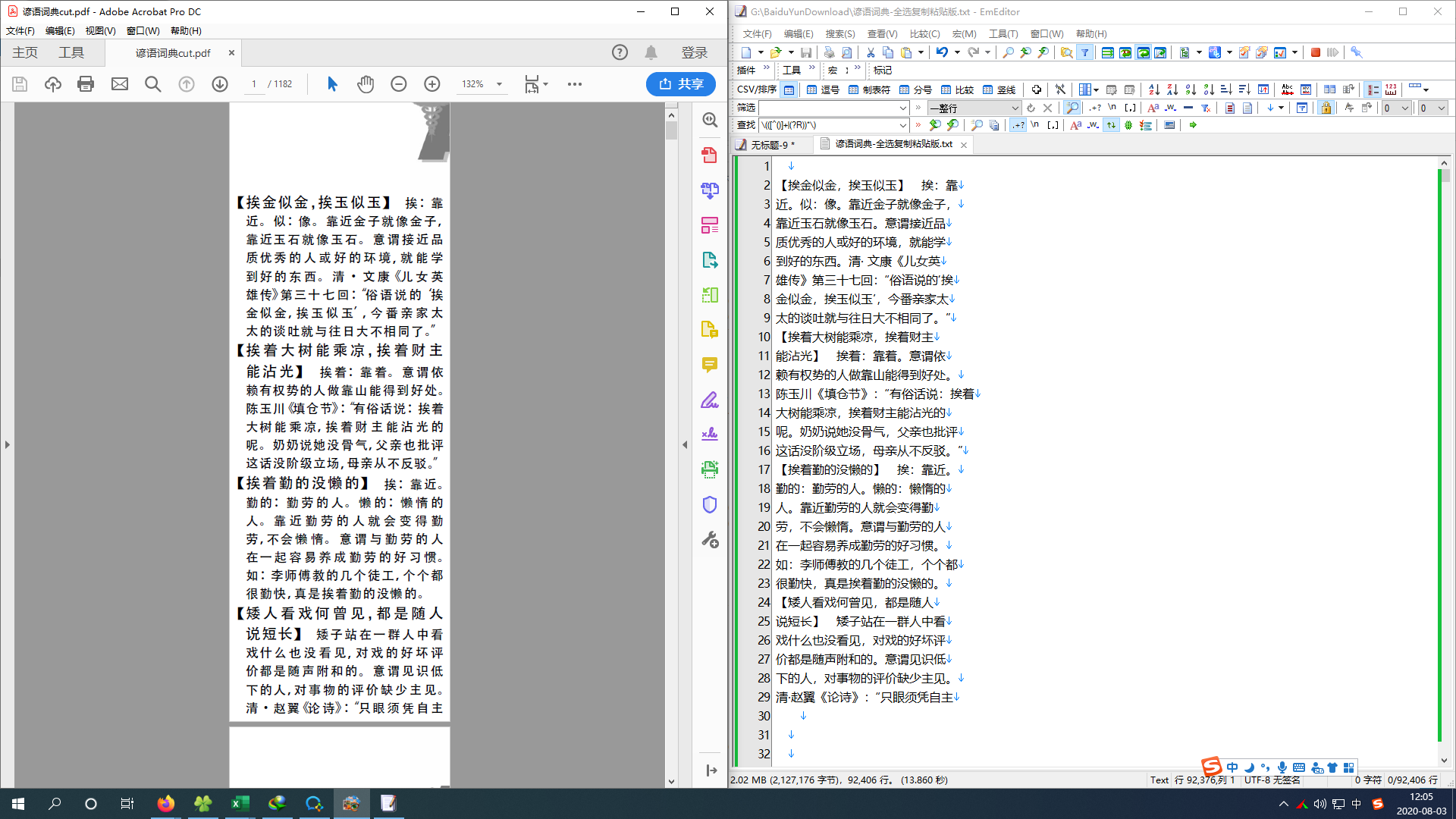
试图将手上一本文字版pdf中的文本完整导出,无需保留排版和格式,只需留下文本内容即可。尝试acrobat直接存为txt,却发现文字和符号会错位。也尝试了好几个pdf to txt的软件,但是效果均不理想。请教论坛高手有什么手段可以解决吗?这是pdf原文截图:' \. C H# ]8 C. Q& q9 d7 u' o
+ t& J6 ^) S. b" d `
 2 W E8 U! T0 K+ h0 ~6 O% V 2 W E8 U! T0 K+ h0 ~6 O% V
8 A, h ], {3 ~9 V6 i3 x% Y/ u" j8 a
! k) Z( y6 f$ M5 D: c/ S" A/ Z3 n' v下面则是转成txt后的效果:5 O+ o. V1 X% A H1 s$ E
+ E! M; k Y% N( P
 " Q# x: L% Q! x" k- z& q " Q# x: L% Q! x" k- z& q
3 V7 a. y7 O, ?2 d4 ?
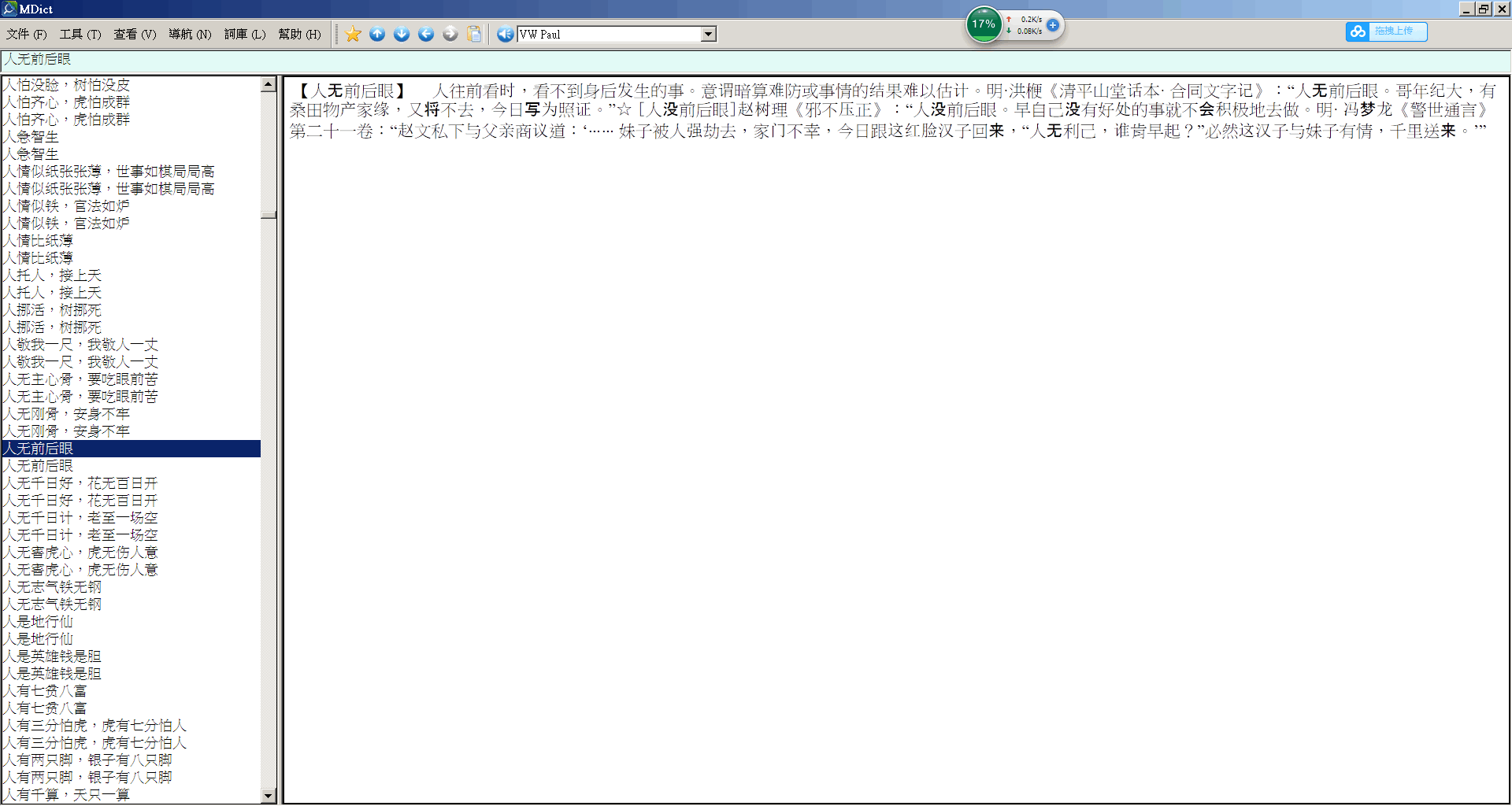
0 V8 b) Q; K0 q1 F6 E! n5 H3 @很明显,尽管我已将原始pdf切了图,文字内容仍然走样,但是直接复制pdf文字,内容是正确的,如下:
: ?$ w) S7 N% r, u$ q
8 b1 x8 I8 e: U【按下葫芦瓢起来】 瓢:把葫芦
; w% X( w: Q% z- ]& R/ A锯成两半,去掉中间的瓤就成了/ J( E$ M- g) J4 ?! x$ W
瓢,可作舀水、舀米的用具。把葫1 ]; G4 _' b+ {$ W; H" g
芦按在水里,瓢又浮起来。意谓刚8 j) P$ {" h% J7 ~) Q
解决了一个问题,另一个问题又出
8 a' p, M$ L# O7 |% s现了。鲍昌《庚子风云》:“瞅准了; M% ~4 L4 s' R9 {% v$ K3 z
时机就扯旗大闹,‘按下葫芦瓢起! H3 g. N$ F7 w# d* [5 V& Z: e
来’,休想让洋人、官府再有个安生1 k; \; ]1 ~/ @* p' b4 s/ E
的日子了。”☆ [按下葫芦浮起瓢]- E' l, W p% @6 t2 K# g" @( k
罗国士等《黑水魂》:“他挖空心思
8 Z2 I3 D) c9 {7 `! ?编了几个理由,才好容易把他稳1 d T/ }& y P, W; H
住。没想到,按下葫芦浮起瓢,门
- D) |5 }$ @8 o% H口好像发大水,乱成一片。”
- ]$ \# Q5 c! }1 O5 d! c
/ p/ P- }0 n7 C( w' g, l" H& ^6 L; n/ p4 ?5 P: O5 W
不知哪位有这方面的经验?请教一二。先行谢过。- I- K# K8 J, |& ]( r' w
# \: X) i. |: r( [2 \' q9 ^
1 S7 J) e+ ~3 m) d; F& V
' a, }; t/ y1 A; u1 v
|
|


 发表于 2020-8-3 06:58:26
发表于 2020-8-3 06:58:26





 楼主
楼主