|
|
本帖最后由 Oeasy 于 2013-11-17 09:54 编辑
$ `, E5 H7 h) u5 k9 C: y& [3 n4 b) O" g3 a: ]. E4 N
7 t: X& ~0 }. j: D D( }) @一个简单得不能再简单的网页抓取然后制作mdx教程(20131114)$ H* a: P0 r3 [/ h$ `- G6 w
$ X, L( ]1 \- G- d% M5 V0 k
使用软件* k# o/ g0 _1 ~) h5 k
0. 操作系统:Windows 7 旗舰版64位
# L3 q+ B) T! K) a7 I6 E5 c/ M1. 抓取工具:wget,http://users.ugent.be/~bpuype/wget/,http://baike.baidu.com/view/1312507.htm, C7 o0 u' r, E' J% y
2. 文本处理:EditPlus, UltraEdit, TextForever(http://www.comicer.com/stronghorse/software/index.htm#TextForever)
9 b% V/ a9 \+ z4 h& D4 d) H
8 u! v# j# X' b# b目标词典; y! T2 S% {- g8 ]" h, }( Z/ B
Dictionary of Phrase and Fable,1894: http://www.infoplease.com/dictionary/brewers/ 这词典是公版的,而且网站没有设置抓取限制(至少目前看来没有设置),获取index也非常容易,故以此为例。
6 y, i8 B( e& `- v7 L( h另:有个pdf http://pan.baidu.com/share/link?shareid=267207&uk=2063908536,版本不详,似乎是第17版的。
- i% T8 p5 \# P/ ^# C. d
: O* B: H3 b, l2 l操作步骤
3 b6 k8 ^4 N' Y( C3 i8 d1. 获取index
! Z; r% G; {! Q; A# ^5 B6 q* `2 v观察http://www.infoplease.com/dictionary/brewers/,该网站本身可以browse整本词典,获取index非常容易。9 @) f+ y; F- E" M5 ]% {
新建一个txt,内容为
' ^5 C! _& y4 W) g* e Q& T# W
! z) y1 t9 T( j- P这些地址都是观察上面网站而得,txt命名为download.txt。
% j" ` |, w% C/ K( G我把这个download.txt和wget.exe(如果你下载的wget是wget+版本号.exe,不妨重命名为wget.exe),这俩文件都放在D:\DOPF下。
0 J" Z4 V7 c9 i4 R4 M, b
, X# v. Q$ K6 c/ r( k6 R" Y0 Gcmd.exe->CD/D D:\DOPF->wget -i download.txt
( N( v# d/ k( \! @
: U- I9 j' C4 S, E1 J* f" l很快,26个html文件就下下来了,对这26个html文件进行整理,得到
7 z3 R3 Y; S& T6 h' t N2 [8 ?) v5 {
这样的一共16698个链接。
" u# Q' z9 u& ]( x8 W* ^8 \+ ? J: W" K& m* ~1 \
2. 抓取内容( E5 q4 s9 ] Q
同样的,wget -i download.txt/ y4 p8 ^3 V q! C$ ?$ m4 Q
把上面那N个html都抓下来,然后就很简单了。
5 {: {6 u# ^# ~' T( j-2013年11月14日 16:35:47! x3 M5 P- i! z$ A& u. n
成功抓取了16695个html,漏了3个,懒得研究到底是哪3个了。
6 U8 q% z6 i* e6 \" U* z1 L) X$ k: V. T4 c7 V& L4 u+ z' o' ~# c
3. 文本提取
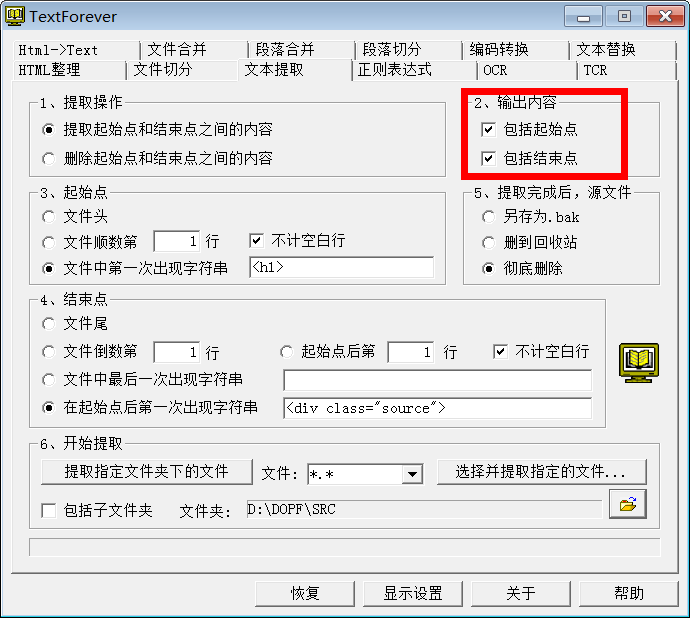
; v1 O& A* X7 U3 B6 \1 E9 e观察可知,词典条目内容在第一个<h1>和<div class="source">之间
( `9 L4 [, X4 ^<h1>Charybdis</h1>" ~: a1 {% b1 I5 H/ ?' c9 ]1 r
. K- P: p, k& o<p> [ch=k]. A whirlpool on the coast of Sicily. Scylla and5 X1 ~, H5 q1 D5 g7 Y
Charybdis are employed to signify two equal dangers. Thus Horace says! I% E2 M7 [0 e/ j
an author trying to avoid Scylla, drifts into Charybdis,<em> i.e.</em>
; {1 B8 ?# n7 n& ?& G# c# H3 yseeking to avoid one fault, falls into another. The tale is that7 p' D+ I0 t( k9 H" o
Charybdis stole the oxen of Hercules, was killed by lightning, and
9 `8 s( k3 h" Echanged into the gulf.</p>1 l# q6 h- O% b6 v G) M3 p
<p>“Thus when I shun Scylla, your father, I fall into Charybdis, your
T- R9 B4 x) L6 ~; \6 ?; O" p+ Imother.” —<cite>Shakespeare: Merchant of Venice,</cite> iii. 5.8 P( n7 O- `' O1 w( r, J; |. |
</p>5 L& C% ~5 _" C$ J2 V# b h3 E
( t5 F- a" E( J
<div class="source">Source: <cite>Dictionary of Phrase and Fable</cite>, E. Cobham Brewer, 1894</div>
利用TextForever来提取文本8 ~ g: c" ? q& W2 t
 3 _$ B! J+ S6 T' _: e- s6 r, x 3 _$ B! J+ S6 T' _: e- s6 r, x
-& }0 p, d/ t& `, ?
 ( ~3 Y0 m5 v. {/ i* v+ g ( ~3 Y0 m5 v. {/ i* v+ g
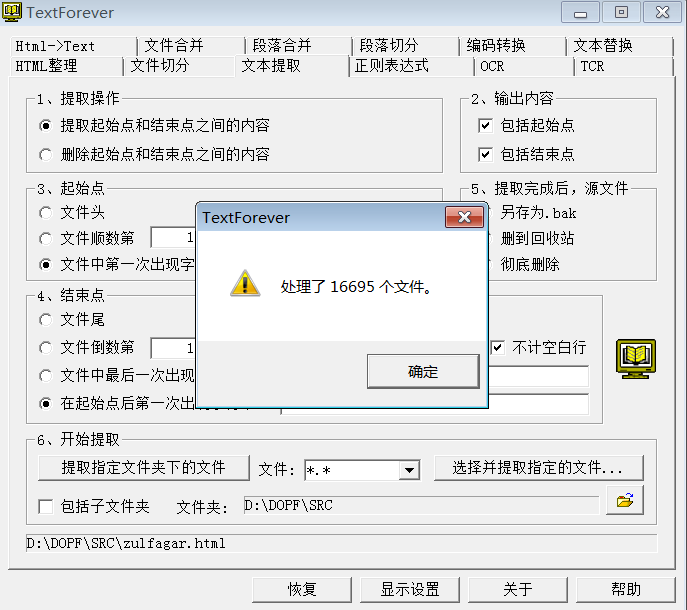
提取完毕,合并得到的16695个html,7 n: u0 `- A- ~+ [, L: v0 p+ f7 T6 w
 " R1 @% s& c% d+ f) a " R1 @% s& c% d+ f) a
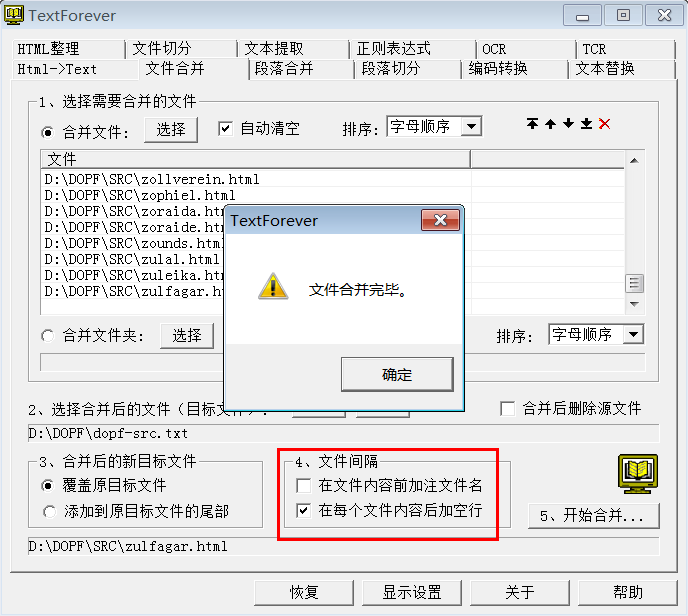
这本词典的制作过程中,我思考了下,不用在“文件内容前加注文件名”,有的情况下,是需要这样做的,以方便提取keywords,经过测试,还是要在“文件内容后加空行”。& m- g4 i' }2 I4 W
 . ?( b% u) z- E2 w/ U5 [! o% D7 c . ?( b% u) z- E2 w/ U5 [! o% D7 c
得到dopf-src.txt,对这个txt进行操作,得到可build为mdx的txt。
4 P. B: |( b6 V3 {# w! |" _' r2 B6 e1 I- w4 g7 I' @( G- m- n: A
4. 制作mdx
; e4 V* V8 A) M1 p* t, b合并后的文本长这样:* E8 J8 @; X' R7 S+ \8 v3 [
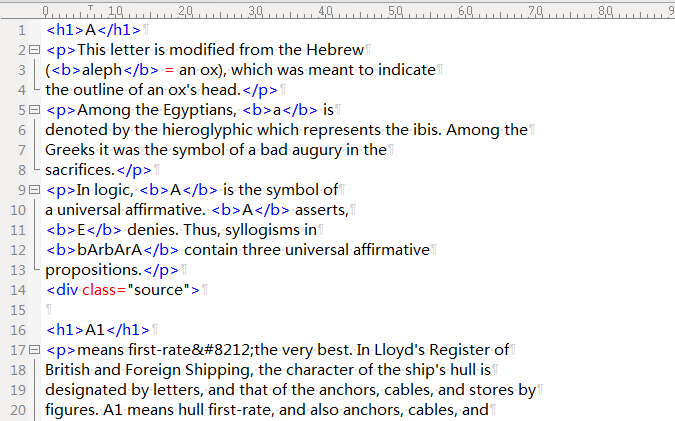 # o9 r: J( U$ W8 F- t8 J5 _2 P8 F! c # o9 r: J( U$ W8 F- t8 J5 _2 P8 F! c
 ( ^6 A4 o( F& j+ y7 L! V; R$ a ( ^6 A4 o( F& j+ y7 L! V; R$ a
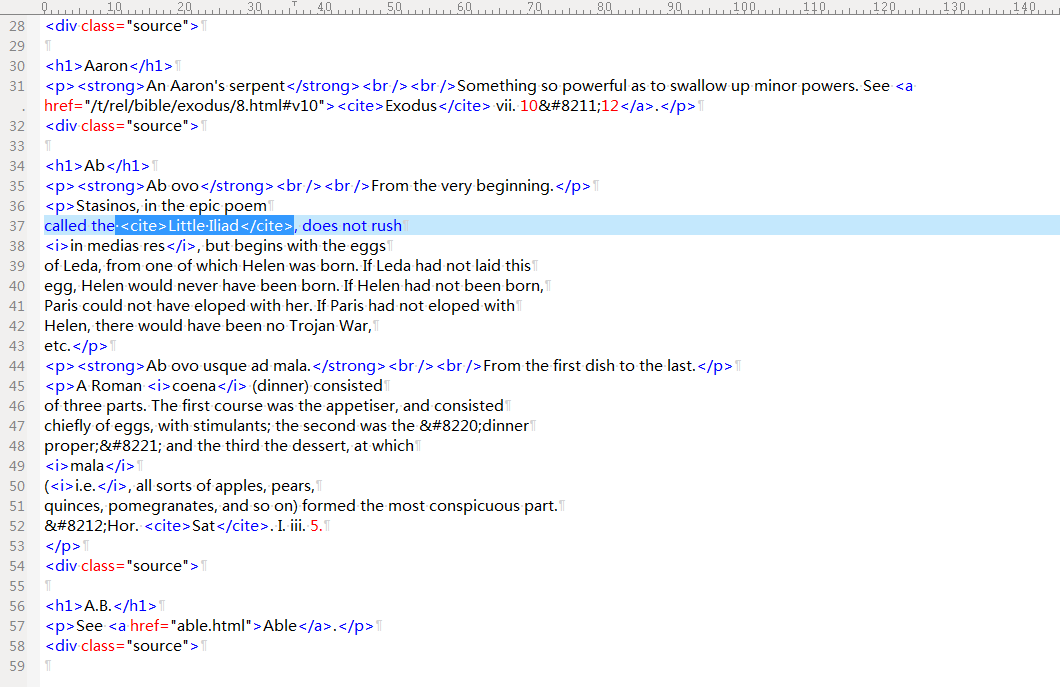
明显http://www.infoplease.com/dictionary/brewers/的词典是xml,由于MDict PC版不支持xml+css,我们要把xml标签替换为html标签。经过下面一系列的操作。& y8 l% F* _) R- _1 h3 t
 * K; p% f% p) b2 D; P) o * K; p% f% p) b2 D; P) o
+ V( x$ |* ]( F) C3 h8 |处理后最终的文本是这样:% s; N3 I$ K; C: |, W+ }
 0 [, S! |+ n" w 0 [, S! |+ n" w
. b3 Z, L* P4 D8 N再简单写点css
/ c1 u& R9 b* Q B$ ^' c+ M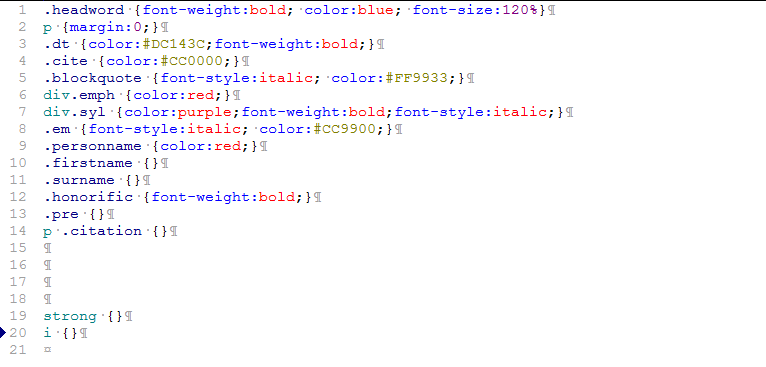 1 ]' a( w0 j1 b' j 1 ]' a( w0 j1 b' j
. l g( h+ [1 P. ~% g3 k f
中途遇到些小问题,一个个解决,最后,成品:5 o, S& d- j$ m& \. m
 * [3 A6 Z4 k' c" E8 r9 g * [3 A6 Z4 k' c" E8 r9 g
是不是比在线的稍微顺眼点呢?& Y, |1 f3 U- _ r3 A
http://www.infoplease.com/dictionary/brewers/comb.html
2 U0 l% X1 v! V! r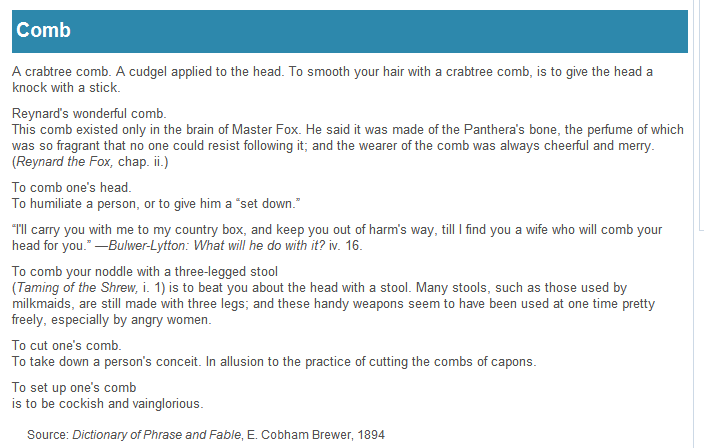
) ^) ^6 T, `3 C9 o
2 A& r' B2 V e0 \+ `. gPS:虽然做完了,但是我发现了一些问题,从上面的截图中就可以看出来,有些词之间少了空格。暂无意修改,等有空改完了再分享。谁有兴趣改一改练练手的话,可以PM我,我把下载的网页发给你。
( w" k, m4 q& ~; ` n |
|


 发表于 2013-11-14 08:24:13
发表于 2013-11-14 08:24:13

 楼主
楼主