|
|
本帖最后由 bt4baidu 于 2015-11-22 10:08 编辑 % T! r/ R7 k( _! J- w9 h- I
1 L G& T" _5 O% Q) T+ S' d0 s这篇文章主要是给计算机小白和初学者扫盲。( c1 |% c$ _0 q1 O% y
本人尽量写得浅显一点, 希望完全没接触过计算机编程的文科生也可以看懂。
. W9 h7 k- H( ]/ w& n1 ?只讲原理和思路, 具体的编程语言、语法之类的问题自己找资料解决,网上到处都是。
" {* D4 c$ p+ V4 U
! ~. y0 L' _5 B" R一、计算机的两个终极哲学问题
& `5 X3 O, R3 C; _1 K1936年,图灵在他的重要论文《论可计算数及其在判定问题上的应用》里,提出著名的“图灵机”的设想。
6 U; W/ z3 W Y. J( a# E4 `图灵机被公认为现代计算机的原型,它的工作原理简单来说是这样的:! S S9 {' v) ?, X/ F+ Z. c. z
设想一条无限长的纸带,上面分成了一个个的小方格,方格有两种:空白的和上面有“—”的;6 k5 h# }6 {9 g- F1 }3 N4 b
机器读入纸带上的方格信息,根据这些信息, 结合自己的内部状态查找程序表,输出计算结果。: O _( X; R7 k' j
方格信息代表了解决某一问题所需要的步骤,这样进行下去,就可以模拟人类的任何计算过程。' R% H# ]3 M3 X1 M7 D7 H
“纸带方格”代表外部输入,“内部状态查找程序表”代表算法——也就是程序,要靠人来写的。5 a5 Z6 ]$ o4 [0 U7 c1 h
4 X5 { F' d: d3 \/ W) V! t
那么要写出程序,立即就会发现不得不解决两个问题:$ u* Y/ V" S# u/ d3 u$ C
1、怎么知道机器当前读入的是哪个方格?怎么读到具体某一个方格?也就是寻址。+ o( ]% f" C. D2 L9 u
2、怎么把两种方格区分开?也就是特征识别。" T( y7 J, E& n/ C
这两个问题,就是计算机的终极哲学问题。
- L" m9 u$ N# o7 b% j6 k理论上,所有的计算机程序问题都可以逐步分解下去,最终分解为这两个基本问题。2 P0 W* |+ z. {( X# Z. a5 }0 |
下面的讲解也会以这两个问题为核心展开。
( R0 X) S( W8 _ y, D' V5 d: }' @/ ]0 Q. U( l3 p
BTW, 如果你能想通这两个问题,遇到编程问题都可以这样子分解一下,把自己想象成一台图灵机,
& P7 J, e' ]: x6 ^; ]* H——所谓“采用程序化思维”,也就相当于打通了任督二脉,立即具有了至少10年的编程内功。
' J7 Z+ N3 p7 O3 a所谓编程,本质上就是一种读取、存放、组织、区分数据,然后按照具体业务计算出结果的活动。. y: K& o2 m1 c4 ?$ Z' V% `
前者是核心,“我强烈建议围绕着数据来设计代码,而不是反其道而行之...坏程序员总是担心他们的代码,
) N& l/ T& Y0 v; y1 \! a而优秀的程序员则会担心数据结构和它们之间的关系。”——Linus曰。
! O& b, z0 I \3 _" ^6 l5 p具体的招式,也就是某种具体编程语言的语法,花个半天功夫就能学会的。" s9 p% v2 O! Y* E+ o
& |1 N% ~6 S+ `9 Y, L# t0 C3 d不要觉得自己上学时学的不是这个,or文科生,就不行。" ?' L* f8 V2 X. a
江民杀毒软件大家想必都听说过。
+ I4 R* k% p' V7 g) D创始人王江民同志,初中毕业,38岁才开始自学计算机,不出几年,就成为中国最早的反病毒专家。
9 y8 F C( s: ^' Z. a咱不奢望成为专家,写写程序总还是可以的吧?2 q2 {0 b/ V, O" c- l, g
& f# b e9 m2 S+ l二、采用何种编程语言
$ l1 R \8 X D上面已经说过,存放、读取、组织、区分数据是编程的核心问题。+ n( h0 X2 k7 w. _. P
显然,能够方便的进行上述四种活动的编程语言就是最好用、最易上手的编程语言。$ }0 y( @1 H* m6 h
抓网站,恐怕没有哪种语言比Python更方便。
. v3 F, e! b% Y$ `1 {7 ]* t7 u当然,你要愿意,用C语言也不是不可以,不过可不是那么容易上手,% F1 L1 u4 n m5 S" I# W1 J+ r
计算机专业的学生,有些到了大四毕业居然还搞不清何为指针、何为引用...这些家伙还是趁早转行,
1 G" m6 @, c( P! A没有慧根就别吃这碗饭。* d$ q! Q* ^, J8 z0 z A
0 Q6 m4 y( s8 K _, ~5 K! x
三、网站抓取技术
j' X& p. [1 ^3 u8 ?7 K; `1、下载某一个网页,提取其内容
3 L+ m( q% z x+ J: F以前写过一篇,就不重复了。参考:& e8 w% S0 p- ~! t" v1 s0 `
用一个简单的例子讲讲怎样从网站上扒数据: {+ M: |% p7 Y& q* j
8 o! \; B; f( t8 O' B4 Q
2、寻址问题( m6 `7 |* C6 q1 u, \
下载网页,自然首先要知道网址,也就是东西放在哪儿。
7 h1 Q# |/ E" g) B+ y' P如果事先有个单词总表,那是最简单不过,立即就可以根据网站的网址规则拼出来。
1 J$ ~; ~9 n$ t& B& ]但是大部分在线词典,到底收了多少单词,事先是完全不知道的,1 X( @6 }8 M/ p& v% \2 p; k
要把单词弄全,就要想办法得到每个单词的网址。
! \, h. H! X) I9 t: b. W8 K总结各主流词典网站,大概可以分为这么几类:! p* Y8 B& E. o' C9 }1 x/ C
I. 事先有单词总表
3 k6 d, `) {) E/ c5 x, @6 D比如http://www.vocabulary.com就是这种类型。
" x+ x# U$ D5 D! O- W4 o1 }" h& M" O K它是在wordnet3.0的基础上编纂的,直接用wordnet3.0的词汇表拼网址就可以。
( K9 W; g+ J5 q' k9 `8 H
8 J( v" L. S; \* Y9 G/ nII. 网站有索引页面
| ?, Z; m. r D( a+ V# @5 ?如:
6 U( p& \! O5 D7 e8 X" nOALD(http://www.oxfordlearnersdictionaries.com/)1 I" r' G, g$ ?$ Y; C
它的索引页在 http://www.oxfordlearnersdictionaries.com/browse/english/
. F$ T) x8 y3 t TLDOCE(http://global.longmandictionaries.com/)
Y! j0 j" S0 {采用框架结构,左侧边栏就是索引页1 L: D$ G: e) K( Y; t% `* R
MWC(http://www.merriam-webster.com)1 `% b+ X0 B) T/ p* l9 Z
索引页在 http://www.merriam-webster.com/browse/dictionary/
: e% ^. B9 @+ \4 y等等
4 H4 z P; m- {这类也容易搞,思路是先从索引页得到单词表和网址,再一个个下载。% v! _' g) N+ `) K, U7 }+ r8 U
3 m" D* m% f! k) T3 b! B& E- urls = []
: m, V+ F5 @( Z6 }- }; f - for someindex in indexs: # 循环所有索引页0 R! \' p6 U# U9 W3 U! [
- browseurl = ''.join(['http://somewebsite.com/', someindex])
2 I0 y" | K* y8 m' W" a8 A - browsepage = getpage(browseurl) # 下载索引页面
: Z: U% B |/ E0 x1 A( v7 C5 x - target = SoupStrainer('sometag', class_='target') # 抠出放单词链接的区域
6 k- |! W$ I8 S8 U - bs = BeautifulSoup(browsepage, parse_only=target)" F- y' v: Q" \: x! k
- if bs:5 A. A; j( P9 ~! c7 j* Y
- for a in bs.find_all('a'):
; ~9 D( b( }2 Z& X1 H% @ - urls.append((a.string, a['href'])) # 取得该索引页上全部单词及链接
3 x* i( _4 ]4 {8 E: y7 Q - 然后:! ?" E6 U M" {" Y$ | Q
- for url in urls: # 循环所有单词, W3 S! i8 O# p
- wordpage = getpage(url) # 下载单词页面
- `9 y2 g& s0 E9 B6 b# d6 i
2 v* a- c, r. Q3 c1 G$ N. d# }, q1 T( U
III. 索引页和单词释义一体型网站3 |# F+ K1 b: T. a8 S: A
如:Online Etymology(http://www.etymonline.com/)" n; t4 R! Y2 o, m0 n+ E
和上述II.处理方式相同,在循环索引页的过程中把单词抠出来即可
, M8 e; I" _+ }4 a9 P
" M7 M. {3 e9 h& h( r# e0 T; G- for someindex in indexs: # 循环所有索引页
- E( I+ o/ x+ i6 H - browseurl = ''.join(['http://somewebsite.com/', someindex])$ [: T. y" U( J
- page = getpage(browseurl) # 下载页面: U5 y8 L+ I8 B! ~! K
- target = SoupStrainer('sometag', class_='target') # 抠出放单词的区域
# J( Z" f% O& H3 c - bs = BeautifulSoup(page, parse_only=target)5 t4 S: w# g0 e# M
- for tag in bs.find_all(target): # 循环抠出单词; j& R" j+ s% T }( |; w" E- c) U
- worddefine = getworddefine(tag)
% d* D/ e! b2 E1 h( ?4 |
" {; r* o5 E+ H/ p; n9 x& H0 J/ _, r
IV. 片断索引型网站
% T) J2 R7 \# v8 T8 N4 m3 c如:% Q( ?% ]6 ~4 y7 b/ [
ODE(http://www.oxforddictionaries.com/)
2 Z. c2 X% ?3 h; J- F每查一个单词,右侧边栏有个Nearby words: Q( J( y) G. _2 f
RHD(http://dictionary.reference.com/)
0 x) i z& e% v/ h2 l5 K+ m# U右侧边栏有Nearby words. e- |( T) W- v) G" P. O
CALD(http://dictionary.cambridge.org/)+ a* E- ~! k& D4 | C# r' E
在页面的最下面有个Browse栏,给出前后相邻的单词: i, I$ U- A8 y2 u
这类网站没有总索引,只好利用它的Nearby栏。
1 L, N8 s3 G: ~思路是从第一个单词(一般为‘a’或者符号数字之类的)开始抓,
2 j0 ?, V% f% g: C每抓一个单词,同时得到下一个单词的网址,直到最后一个单词结束(一般为‘zzz’什么的)
- J2 o8 h. b* p$ X ?, ]- . O( l0 U5 p& x$ ]0 m0 h8 l
- cur = 'a'
7 i. f) N* `" C, {* M - end = 'z'" u' [+ [% b! P2 k5 q
- nexturl = ''.join(['http://somewebsite.com/', cur])% Y5 p% @8 h U. D h. K+ J% A
- while cur!=end and nexturl:& \( h' t, F5 Z/ I, [
- page = getpage(nexturl) # 下载单词页面7 P" J( b0 z% z/ L' u3 e9 |
- worddefine, cur, nexturl = getword(page) # 得到本单词释义、下一个单词及其链接% ]6 _6 N* D z4 \, m2 k
. D* E) r& B- X. s$ U, [# {$ M) K6 v$ I- r6 [" ]
V. 完全没有任何索引,那就没法子了
) E8 M0 ]3 L$ ^4 y8 A9 R% u2 H当然穷举算是一个办法,自己搞一个庞大的单词表,然后按I.的步骤处理
* c1 ^) W6 M; ^; w5 P理论上也是可以的,就是效率差一点;
% d u4 h8 o+ Y) X+ m另外各家新词收录情况不一,有些词组、短语拼法也不太一致,单词表准备得不充分就没法完全网罗。6 Q$ b. G4 n( W$ D6 m" M5 L; |
( \: q8 M; y3 _6 H
3、提高下载效率
/ q! g8 Y. [; i- d( @- z: m0 ^I. 多进程
! { J- b9 u5 {7 _# u" P6 Z上面写的都是伪代码,也就是简单示范一下处理流程,直接写个循环了事。/ j2 L. y, q/ O: F+ J, ?
实际抓网站时,这么做效率显然是非常低的。2 x& a* ?% ?3 r0 Z1 L' o& T
假如有十万个单词,每个单词需要1秒,循环十万次就是差不多28小时,要花掉一天,
5 ^! [) T( q- s6 c; S9 E有些网站还经常抽风,半分钟下载不了一个单词,那就更慢。
/ Z% L u- g" D假如在这段时间内,你家猫咪把电源插头给挠掉,或者键盘被女秘书不小心坐到了呢?) q2 J7 [5 ~2 z( f
要速战速决,就得开多进程。
9 n7 ^& J' i: r n同样十万个单词,分成25个进程下,也就是28/25=1个多小时。
) p X3 v4 E8 M* L! M3 o, ~/ p) v E再开多一点呢?岂不更快。。。那样硬盘就转不动了,所以也是有极限的,要看PC的配置。$ c+ ~! U1 V9 L) s# i! K# \
在Python里开多进程,同样十分简单,
& S9 g5 U! ^# E, v9 ?- G- ( K- l( D% L& g
- from multiprocessing import Pool# ?5 e/ S$ l1 c# G1 s( C W! l
- pool = Pool(25) # 开25个进程" J, u5 z* L. j3 ~% R# z
- pool.map(downloadloop, args) # downloadloop是下载函数,args是其参数2 c2 o0 _' H/ q7 y* w( z0 W/ T
这就搞定了。
+ ^5 Q- F" g0 g m% W1 U0 q$ O! b3 x% c U" }6 ]6 {
对于上述I.~III.,包括V.,分块比较容易,无非是把一个大数组分成25份,
3 n6 F" V! ^ N$ ~/ B关于IV.,事先没有单词总表,就只好采用区间的概念,1 D$ n+ K4 [% T0 Y8 B( L
比如('a', 'b'), ('b', 'c')。。。这样划分若干个区间下载* j( I3 w" t" d+ N6 \
6 C8 u& m: R% r5 R初学编程的人,一碰到进程、线程,常常有种畏惧感,
! V: c4 E. h0 X4 k6 Y& W看到同步锁、共享内存、信号量什么的顿时觉得头大。
4 X0 x/ t- F8 d. \- @! O其实没什么好怕的,这是个寻址问题,关键是搞清楚它的内存空间构造是怎样的,
& M% v5 n: e T/ M+ i其中涉及到一点操作系统、读写互斥、原子操作的概念,找相关的书了解一下即可,没有特别难以理解的。
% j5 O+ t" y/ t$ @3 U( m @
2 h% z; n* z$ b0 \: O. ZII. 断点续传7 ? u: v# n( Z! M' H7 x! ?
事情永远不是那么完美的,网络连接随时有可能中断,网站可能存在瑕疵、死链。( X+ Q2 b) l& i# f- l2 {; N
所以下载程序也要有点容错的功能,最好莫过于可以自行从中断处恢复,完全无需人工干预;/ q- a ~) S* [9 e% O: s
即便无法自行恢复,也得容易手工处理,不然可有的烦了。
$ S7 w2 O4 J" F& T3 F0 O# ?- ?这也是个寻址问题:关键是搞清楚从什么地方断的,把它标记下来;循环检测没下完的区块,从中断处接着下,/ g5 V" q# }; ^# ]
直到所有区块下完。0 r: B1 U7 T" H
, c+ P& L$ {9 \! A! z- def fetch_a_word(part, word, url, data): # 下载一个单词( h+ O) j. e: c# D
- word_define, failed = get_a_word_from_website(word, url)
' Y+ H9 {/ D: n" ^( f$ y' r! k - if failed:) I& A) M* C( \# n$ X6 K
- dump_failed_word(part) # 输出下载失败的单词及网址' N. \ Y7 k$ h7 b
- return False+ A3 e1 e) g# \
- else:+ P/ ?7 ?- _: Y' J; y( M2 S
- data.append(word_define) # 保存下载成功的单词数据9 {! g# ]3 A- C! Y" Q% o J! V
- return True
! i" a6 Z5 b! a% g) g$ S9 { - : W2 E4 E# B4 z6 j/ y& c5 v
- def download(part): # 下载一个区块
9 e/ @" j8 B' m7 s4 i - words = getwordlist(part) # 读取单词总表
& _. I5 Q1 T8 O1 [ - if hasfailed(part):/ x3 R# A2 L- @" V) E3 n
- word, url = read_failed_word(part) # 读取前次下载失败的单词及网址9 S/ t8 R, D5 n; H, e
- else:# w8 G5 w; U0 R% Z$ J6 G/ [4 E# o
- word, url = words[0] # 首次从头下载+ Q7 ?6 U+ p/ {4 _0 e4 `0 }
- data = [] # 用来存放单词定义# g9 B) L t8 ^# z2 H" X1 j9 ^& F
- while not_end(words): # 循环下载
: N! M4 b( i: ]1 G2 r - if not fetch_a_word(part, word, url, data):5 P- e$ G* Y3 b* l+ n
- failed = True
8 o) ^- [5 h2 S+ _ - break& Y; G5 P. }4 v- y% H i7 C' x
- else:
/ S( G! e' n+ n! l - word, url = get_next_word(words) # 准备下一个单词及其网址
+ N- I1 ~1 V7 h1 ^, ?- A - if failed:
& ~! l, i: I1 K4 f7 O* j+ T/ ~7 w7 P - suffix = '.part'
* z$ L: N# m: c/ ]# a& n - dump_data(data, suffix) # 输出下载成功的单词,若因下载失败中断,文件名加后缀'.part'
N) B3 X0 F$ Y1 {* @' s% ]4 ? - 5 t0 z3 A% o F) H1 R$ A
- def isfinished(part) : # 判断某区块是否下载完成
- r8 O/ `/ E$ M - if is_data_file_exists(''.join([path, part])): # 通过检查数据文件有没有生成来判断
: X( P5 z! l/ O5 \4 u" [7 X- i - return True% C( p, m1 L9 n- A2 L
- else:+ N$ j1 J: h# s& |" B
- return False2 c0 w* c5 Z) h% Z
- ! F3 _- h9 _9 U/ a
- def downloadloop(): # 循环检测未下完的区块
; I1 @0 M" ~5 F - finished = 00 |- ? l9 u! u2 \
- while not finished:
/ l b- z4 K; ?5 ]- T- M) a - nf = [] # 没下完的区块
; a& \: R. T, C }1 e& l - for part in parts:* I# g r# t/ J& I/ B9 i" w
- if not isfinished(part):' k6 \ [$ Y- G" Z( r4 v6 v" X. K
- nf.append(part)
; c8 `; U3 H! P1 ?& @' t - finished = not nf
+ q3 U7 k5 J. T/ u. @; \ - for part in nf:; T- |8 C( Y% C4 `
- download(part)
! `) V- W0 t I8 V
/ z: a* e+ c2 c0 u# R# f% fIII. 高速下载网页的小技巧% f$ B7 ^1 _: h1 `2 j' M
Python里面有三个库都可以用来下载网页:urllib2、urllib3和requests。7 V+ w5 N0 M/ G" _1 L
其中urllib2是Python原生的,urllib3和requests为第三方库。5 k) n1 N/ x& A+ Q4 \
(似乎Python3已经把urllib3收编为正规军了)
0 \2 u, \5 `) D* P+ @9 e这三个库有什么区别呢?+ F8 k! C. x* @4 p+ C) r" O
形象点说,urllib2相当于去别人家“拿”东西,开门只拿一件,然后关上门,再开门拿下一件的家伙。
* L0 p# J2 n* \, |9 M0 h: i( M再笨的贼也没有这么干的,不停地开、关门太浪费时间,也容易招警察;同样,频繁连接也会网站被封IP,4 L. H/ c9 |+ _" d
所以urllib3在urllib2基础上加了一个HTTP连接池,保持连接不中断,打开门以后一次拿个够,然后关门走人。: ]$ X& S$ [% V/ b% s2 Y
但是urllib3有个问题,它不支持cookie,所以无法保存用户信息,遇到需要登录的网站就没辙了。
2 f( V/ |+ k( N! X, l这时候就该轮到requests出场。requests在urllib3的基础上又进化了一步,它可以通过session来保存用户信息,0 _, P$ D7 m& \$ v
通吃一切网站。- s& N: _- g9 U
所以你完全可以只用requests,忽略另外两个。不过我一般习惯用urllib3,只在需要登录的时候才用requests。" A1 v6 d3 M* x4 ~* |' }
这仨库的用法都非常简单, 两个第三方库都有齐全的文档可供随时参考,虽然大多数功能都用不到:/ G4 j% q8 k( y6 o. z# h; }
http://urllib3.readthedocs.org/en/latest/
4 i: m9 m9 J; X# ]: p8 b, t: Dhttp://docs.python-requests.org/en/latest/:
% e$ J7 v7 ? T- $ J! Z' B0 g/ ^$ u6 E
- #urllib2( [' Q# s. r( ~; p& _
- import urllib2
1 ]" r: C3 Q6 i g1 H - def getpage(url):
! R6 E# w' e3 H$ E$ V4 f( h - req = urllib2.Request(url)
; ~& e' j! ^% @) y! s p3 m - response = urllib2.urlopen(req)
9 X' F3 g6 T& ~& N - page = response.read()! ~5 H. `) E( j" o# e
; l" g; C- ^' w6 H0 _7 U- #urllib3
1 s O$ I8 [0 U3 n - from urllib3 import PoolManager$ M, C: @+ Z6 o6 F
- http = PoolManager(). R. ` Q$ u H4 Y- ]3 D/ ?# z$ {
- def getpage(http, url):
; B8 Q! X' w6 h* c - r = http.request('GET', url)
3 W2 m: K; S4 _9 Z - if r.status == 200:) P6 S. M! }: D8 i' W. N
- return r.data
) e1 n- F7 ~; n h& E' ^$ m, q - else:
q& b3 d0 I" S# l - return None7 s2 q4 Q9 T7 s# [. _) X
- ( @+ a. d+ a5 e* {' e( w: t2 i
- #requests( L/ R) C t! U7 P
- import requests
. W* ]6 L! M. _+ r - session = requests.Session()0 f; e( H- \9 ?: R# A8 ~
- def getpage(session, url):' `( D, Y* ?/ V4 e
- r = session.get(url, timeout=10)9 h9 Q$ j8 s) F4 @% q% x, d
- if r.status == 200:
' ~& Y4 X( g _$ G, f' E - return r.content
' [4 w) u+ B# c - else:
% d2 \" B; m' F. ? - return None1 G; O+ _+ g; n
& v/ i# v+ z% Y k四、后期制作: x* ~1 l+ C2 p' [1 ?4 p6 l; c; g
1、文本处理,是个特征识别问题。# P6 I. K& \ _
本质上是找到满足某种模式的一串数据,按一定的规则转换成另一种模式。4 p5 m) b5 T/ |- w5 c( g
当前的大热门:生物识别(人脸、指纹、静脉、虹膜。。。)、语音/摄像头输入(智能家电、自动驾驶。。。)3 d6 U+ m8 _6 n, |6 H- ?+ J6 w8 c
都涉及到特征识别问题。1 \- x3 s4 _9 n3 ~! _0 Q2 U% @7 [
相比这些高难度动作,文本处理算是比较简单、基础。: [3 ~* S' a& h& c. @
Python里常用的文本处理技术:正则表达式、BeatifulSoup、lxml
: [/ a3 X0 F J3 |* o8 w正则表达式非常强大,但没法处理递归嵌套的标签型数据7 V, }) t- ^+ p/ U+ {1 D
(如:<div>第1层<div>第2层<div>第3层</div></div>...</div>,这已经不属于正则文法的范畴);$ b' d! n! a- H' A* F
BeatifulSoup/lxml可以处理嵌套的标签型数据,普通文本则无法处理。
# s# N1 k. G; Q3 j3 [+ Y所以常常要结合使用。( I: C4 D" n7 m; {" }
这些难度都不大,关键是胆大心细、思维缜密,不厌其烦,慢工出细活。* v; f4 f6 ~% _: f0 _4 @
, P) @' o9 a# M( E# B% Y0 T1 V
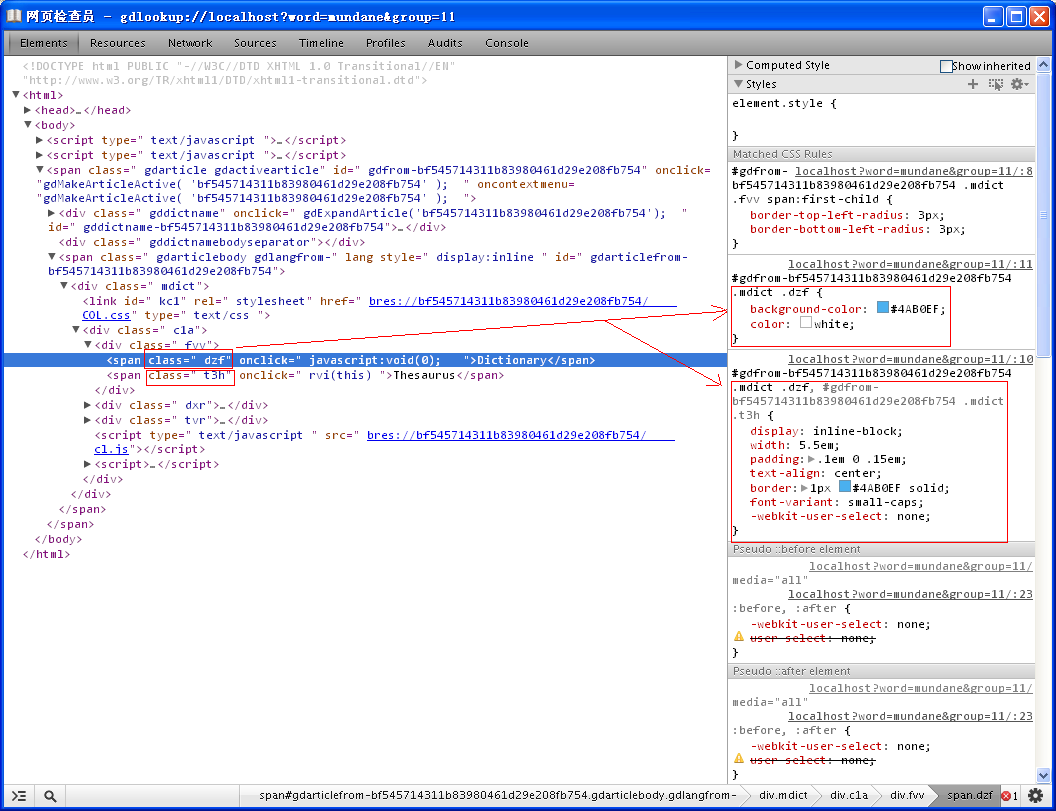
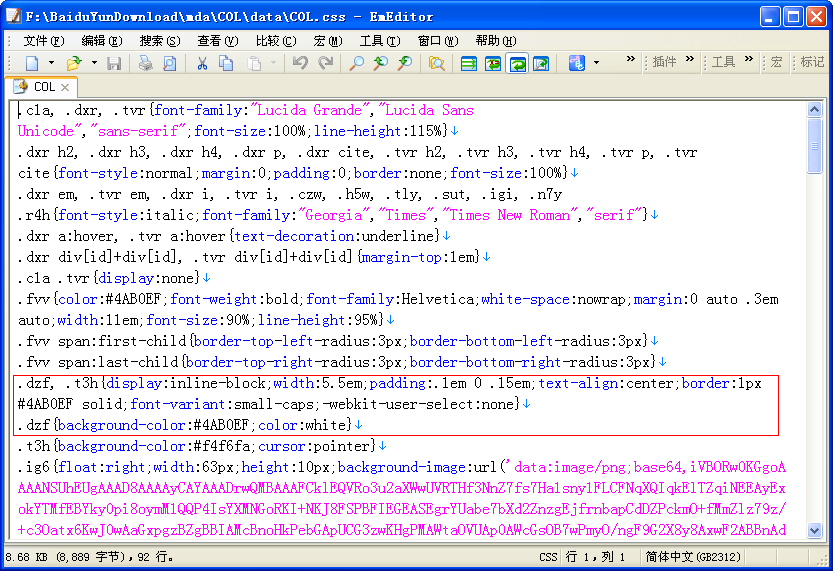
2、排版' J; s$ s& N+ |5 `, Z
HTML、CSS的基础知识:; T, V5 F6 u" N/ W7 G
http://www.w3school.com.cn/html/index.asp# u% k" J* E5 k7 D7 ^
http://www.w3school.com.cn/css/index.asp
4 O# }* l# V7 D2 L- e* [# D! e6 z: i! shttp://www.w3school.com.cn/css3/index.asp
h' V0 F) |. N6 D! u' F+ S% {非常系统、非常全面。
: c3 A3 O& u1 n( U- d4 i6 E排版词典需要用到的HTML/CSS知识并不太多,遇到问题参考上述网站即可。, ^2 |. q9 B. E0 Q9 z7 d
7 S7 c" N v) }, F" n, d
五、结语( r; ^: Y9 y: v9 o; j! f( p3 [$ U
花点时间写个科普文,主要是考虑到确实有些文科同学or计算机小白想制作词典,但没有思路,无从下手。" |2 ?* j& h$ x. |2 ^+ H( x
所谓术业有专攻,为学有先后,总结一点经验分享出来,也算是对社会做点贡献——! k9 f+ L& p3 `$ ` x
大家有个切实可行的方法参照,不至于绕太多弯路,浪费太多时间,从而节约了社会成本。! K( V0 n' D+ C- f; B3 g6 ^- v2 _
8 [7 h" P1 |! S* U/ d打算做万年伸手党的同学,本人也没想过要鼓动你们,继续做伸手党好了,热心人还是挺多的,时常有不错的新作发布。
6 }9 w/ S9 H1 x, O6 A" V8 r4 Z, t* T, {. H; u4 b
只是拜托不要打扰别人,真想要就自己动手。+ X" G! S3 f: p& O* X. i
尤其不要抱着“你手熟,水平高,做得比我快”的想法,觉得找别人做词典就特别理直气壮、理所当然。, C, t- v8 U8 F P# W: k6 T
水平再高也要花时间;同时,水平高也意味着其单位时间的价值要超过水平低的人。+ `' ^, w0 X. e% u0 ~$ m7 D
虽然每个人都觉得自己至高无上,应当受到别人重视,
2 R0 ^& G! `$ k: f其实“在你做出惊天动地的大事、拥有巨大名声之前,你在别人眼里就是个屁”——Bill Gates曰
x5 S0 Z# D7 P G' l6 B1 j
" ]9 e7 U! l7 P* |: J) ^! N# Z6 F7 C( \
========( L* Q% |" \. H+ q
六、拾遗
$ E$ s% J0 j: G关于上述IV. 片断索引型网站,有坛友指出ODE、RHU等都有索引页,因此可以归到第II.类
: C& N4 z/ J# X/ ]' \5 p, G7 U确实如此
2 e" F. f5 y+ Y: ~( a: m5 p不过这里只是举例而已,不用太较真啦
6 @/ N7 [( ?; l' L实际操作过程中,由于网站可能存在索引不全、死链、交叉跳转及数据瑕疵,往往要将II.和IV. 的方法结合起来用,否则不是抓重就是抓漏0 M9 M' J) }& e& U3 B
这种综合性的抓取方法,本人称之为单词表密集轰炸+广度扩展法。
3 q" i" M/ N5 u3 o* N" U5 y即,8 ?. D/ }, k: r! R5 w" h6 o3 r0 S6 { \
第一轮:先从索引页面获取全部的词头(集合A),再用这些词头去网站下载单词,同时提取每个单词页面里指向其它单词的链接(集合B)) l. k- ^% q, Q3 x. M
第二轮:从集合B里删除已在集合A里的词头,得集合C;再用这个集合C里的词头去下载单词,并提取每个页面里的链接(集合D)" e/ _$ |3 F- W4 q4 v
第三轮:从集合D里删除已在集合A和B的并集里的词头,然后重复第二轮的后几步动作/ z# g$ q/ V& K6 y c( j% f% J
。。。
3 U8 R- Y& a9 H直到无法提取到新链接时,结束下载。大部分时候,第二轮结束时就已经提取不到新链接(即集合D为空)
- a0 t5 p8 A( b W最近新做的RHU、CED、WBD,均是采用这种方法,速度快,容错性强,效果极好。; L9 N3 B& g% e" T5 n
形象点说,这种方法相当于草原上先有若干个着火点,这些着火点会把其周围的草地点着,最终烧光整片草原。
2 Q. x; x, c- f/ K4 i因为一开始着火点就已经比较多(索引页的大篇单词表),所以会烧得非常快、非常完整。7 e6 n9 P" Z+ S; H
|
评分
-
4
查看全部评分
-
|

 [复制链接]
[复制链接]


 发表于 2014-10-19 15:25:55
发表于 2014-10-19 15:25:55
 楼主
楼主 ! _3 q8 g5 K1 I+ R; P" W' r6 g' `
! _3 q8 g5 K1 I+ R; P" W' r6 g' `